Páginas
- « primero
- ‹ anterior
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- siguiente ›
- última »
.jpg)
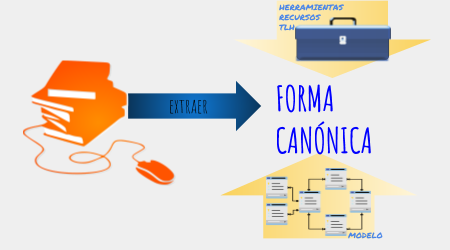
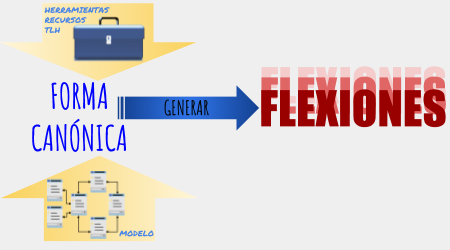
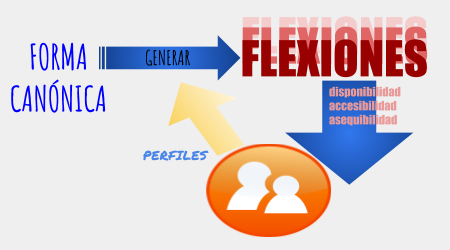
El proyecto RESCATA (Representación canónica y transformaciones de los textos aplicado a las Tecnologías del Lenguaje Humano) con referencia TIN2015-65100-R está parcialmente financiado por la Universidad de Alicante y el gobierno de España a través del Programa Estatal de I+D+i Orientada a los Retos de la Sociedad del Ministerio de Economía, Industria y Competitividad.
![]()
