
GRE16-01: Plataforma inteligente para recuperación, análisis y representación de la información generada por usuarios en Internet
Descripción del proyecto
Actualmente, Internet cuenta con más de 3.566 millones de usuarios , dato que implica que el 48,6% de la población mundial está conectada a la red de redes y por consiguiente consumiendo y generando información. Estos datos han ido en ascenso continuo desde su aparición, identificándose un crecimiento entre el 2000 y 2016 de un 887%. En Internet existen varios tipos de escenarios. Estos entre otros van desde los juegos online y descargas de aplicaciones informáticas hasta los escenarios en los que los propios usuarios forman parte activa en la creación de contenidos. Es este caso nos referimos a la Web 2.0 (o Web social). Bajo la estela de posibilidades que ofrece la Web Social se han creado nuevos sitios Web dónde los usuarios juegan un papel primordial. En ellos, estos pueden participar, interactuar e intercambiar información con otros usuarios (por ejemplo, foros, blogs, redes sociales, microblogs, etc.).
Dado el atractivo de este tipo de Web se ha notado un importante incremento de en la cantidad de Contenidos Generados por Usuarios, en Inglés User Generated Content (UGC), que se publican en la Web 2.0. Por ejemplo si se analizan los datos de dos de las redes sociales más conocidas hoy en día como Twitter y Facebook , encontramos que Twitter cuenta con más de 310 millones de usuarios activos, que generan 500 millones de tweets al día , mientras que Facebook cuenta con más de 1.590 millones de usuarios y más de 74 millones de páginas . Estos son sólo dos ejemplos representativos de dos redes sociales. Si a ello le sumamos el resto de sitios Web, incluyendo otros tipo de redes sociales, páginas Web, enciclopedias, blogs, foros, contenido multimedia, etc. encontramos más de 3.14 billones de páginas Web indexadas .
Sin embargo, el principal inconveniente de toda esta gran cantidad de información disponible es la complejidad para poder analizarla, sobre todo si el usuario desea obtener información precisa sobre datos formulados en lenguaje natural que necesiten ser interpretados. Dicha información se encuentra en distintas fuentes de información de distinta naturaleza y en distintos idiomas. Estos factores, junto a la redundancia existente en la Web y las opiniones y hechos contradictorios que aparecen, hacen que los usuarios inviertan mucho más tiempo de lo deseado analizando la información para seleccionar aquella que sea de su interés.
Un modo de reducir el tiempo invertido por los usuarios en analizar grandes cantidades de información es mediante el uso de las Tecnologías del Lenguaje Humano (TLH). Estas tecnologías son fundamentales para manejar dicha información de manera eficiente y efectiva, puesto que se encargan de procesar el lenguaje humano de forma automática. Esta área de investigación es una subdisciplina de la Inteligencia Artificial que investiga y formula mecanismos computacionalmente efectivos para facilitar la interrelación hombre-máquina, permitiendo una comunicación mucho más fluida y menos rígida que los lenguajes formales. Las herramientas y recursos desarrollados en los últimos años han permitido mejorar los procesos de búsqueda, recuperación y extracción de información, clasificación de textos, detección y minería de opiniones, o síntesis de información, así como los procesos intermedios involucrados en cada una de estas tareas tales como el análisis semántico, que son clave para su correcto funcionamiento. Referente al aumento de la cantidad y la diversidad de los contenidos de la Web, es necesario adaptar la información teniendo en cuenta las necesidades e intereses de los usuarios.
La investigación que existe actualmente suele centrarse en elementos cada vez más específicos dentro de las tareas antes mencionadas, pero dadas las necesidades del contexto actual, donde la información crece a un ritmo exponencial, es necesario aunar esfuerzos en las distintas tareas hacia la creación de una plataforma capaz de identificar el tipo de información que necesita el usuario, recuperarla, procesarla y presentársela de manera adecuada y flexible. De esta manera el usuario podrá, por un lado, ahorrar tiempo de procesamiento y análisis y, por otro, pueda obtener información contrastada de utilidad para sus intereses. Para que la información se pueda presentar de manera flexible y acorde con los intereses de los usuarios se hace necesario que se apliquen diferentes procesos de análisis de TLH que permitan recuperar información generada por usuarios para su posterior almacenamiento y análisis. De tal manera, que se pueda recuperar, seleccionar y proporcionar un tipo de información u otro dependiendo de las preferencias que tenga el usuario. Existe un aspecto muy importante a tener en cuenta en todo este proceso de recuperación y análisis de texto. Es referente al modo de almacenamiento de la información. Dado que la cantidad de datos que se pretende procesar bajo este tipo de enfoques es inmensa, para su explotación y posterior uso esta se debe manipular con tecnologías de Minería de Datos en con equipamientos computacionales potentes, capaces de proporcionar funcionalidades para un acceso rápido y eficiente de la información previamente procesada desde una óptica analítica.
Hoy en día existen algunas herramientas finales que de una manera u otra son capaces de incorporar tecnologías de TLH para proporcionar infraestructuras analíticas. Por ejemplo Atribus que es capaz de rastrear, buscar, recoger, filtrar y devolver todo lo que se está diciendo de un cliente en la red a partir de las palabras clave para cada uno en tiempo real; Natural Opinions que analiza todo lo que se está diciendo en cada momento en Internet sobre una persona, una marca, una institución o un producto, y detectar automáticamente las entidades, conceptos y opiniones más relevantes; Textalytics el cual se presenta como un motor de análisis de texto que extrae elementos con significado de cualquier contenido y lo estructura para que puedas procesarlo y gestionarlo fácilmente; Sentiment viz propone un medios estimar y visualizar el sentimiento asociado a textos cortos e incompletos, Tweet Reach permite obtener informes estadísticos a partir del análisis de twitter, SocialBro que propone una solución avanzada para la gestión y el análisis de comunidades de Twitter, permitiendo a los profesionales del Marketing y el Social Media analizar a fondo sus contactos, gestionarlos y definir sus estrategias en función de ello; SumAll obtiene estadísticas sobre seguidores de las redes Facebook, Instagram , Twitter, LinkedIn , YouTube y Google Analytics ,como son números de me gustas, cantidad de mensajes, localidades, etc. y los muestra por medios de gráficas de intervalos de tiempo (días, semanas, meses).
Podemos concluir una vez a analizados estos precedentes prácticos que nuestra propuesta estaría básicamente más alineada con las soluciones de Atribus y Natural Opinions. Y además podríamos ser capaces de aportar con la plataforma de TLH valores añadidos como:
- Nube de conceptos vs nubes de palabras/etiquetas
- Dominios relevantes
- Mapas de emociones (clasificación de tipos de emociones vs. Simple clasificación de polaridad)
- Extracción de mensajes de usuarios más relevantes en un intervalo de tiempo (resumen de tweets)
- Mapas de felicidad donde geográficamente se puedan representar las emociones expresadas o inferidas de los usuarios de las redes sociales
- Detección de conjunto de términos que caracterizan e indican una localidad (e.g. postiguet, hogueras, arroz → Alicante) vs. Simple geolocalización que proporciona Twitter
Conocemos que en la actualidad muchas empresas se preocupan considerablemente por su reputación en la Web 2.0, ya que las redes se han convertido en las vías más populares, rápidas y efectivas de marketing. Es por ello que nuevos perfiles laborales surgen de la mano de las nuevas tecnologías. Por ejemplo, podemos mencionar la figura del analista social , que realiza entre otras funciones tiene como objetivo:
- Analizar las tendencias del mercado a través de los medios sociales.
- Realizar informes sobre las diferentes comunidades y perfiles.
- Evaluar y proponer mejoras para la estrategia en social media.
- Monitorizar y recoger información sobre: marca, productos, competencia y sector.
- Evaluar las campañas de social media.
- Planificar y mejorar las prácticas de medición por proyecto.
- Clasificar las consultas de los clientes para mejorar los sistemas de atención técnica.
- Diseñar herramientas de monitorización y métricas.
- Analizar la reputación online.
- Evaluar la calidad de la atención al cliente en medios sociales.
- Realizar análisis sectoriales y comparativas con la competencia.
- Medir y analizar los procesos de recomendación
Si analizamos el escenario en que un analista social, necesite, por ejemplo de la red social Twitter, información relacionada con entidades específicas como partidos políticos. El analista podría entonces desear conocer el número de mensajes con críticas positivas/negativas hacia dichas entidades, relacionado a ellos también conocer de qué localidades se han emitido dichos mensajes, qué frases son las más comunes y con qué frecuencia. Además podría desear conocer qué otras entidades, usuarios o eventos podrían estar relacionados con esta búsqueda, entre otras muchas preguntas que nos podríamos hacer los seres humanos, si fuésemos capaces de leer y retener en la mente la convergencia de miles y millones de patrones textuales y estadísticos para obtener conclusiones sobre dichos aspectos.
Puede que a los seres humanos el proceso antes mencionado les sea muy difícil o quizás imposible, cuando se trate de analizar grandes cantidades de información textual, pero si se aplican las tecnologías adecuadas, orquestadas debidamente sí, que es posible alcanzar tales metas. Esto hace que nos planteemos en este proyecto la creación de una infraestructura informática donde convivan diferentes tecnologías de TLH para ser capaces de extraer automáticamente UGC de la Web Social según los intereses definidos por los usuarios. Dicha información sería posteriormente procesada con técnicas de TLH para obtener metadatos que sintetizan dicha información estadísticamente y proceder con la representación visual de interfaces analíticas adaptadas al usuario.
A continuación, se ilustra la plataforma de TLH propuesta, donde podemos observar que de poder llevarla a cabo, ésta permitiría a los usuarios extraer informaciones que se encuentren dispersas en el inmenso espacio de Internet en concreto en la Web Social y visualizarlas desde un punto de vista analítico, tras un intenso procesamiento de los UGC.
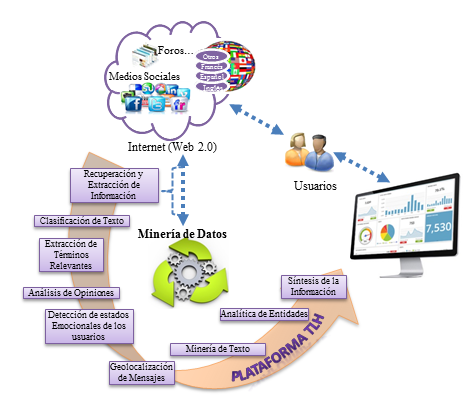
Las herramientas y procesos de TLH son el elemento central de este proyecto, ya que en él se tienen en cuenta tres roles fundamentales. El primero es relacionado con la extracción y recuperación de UGC. La plataforma de TLH debe ser capaz de ofrecer mecanismos para que los usuarios puedan definir sus propias búsquedas de información y de este modo el sistema pueda recuperar y extraer la información precisa. El segundo rol es concerniente a la posibilidad de permitir se puedan considerar diferentes tipos de tecnologías de TLH con el fin de poder aplicar Minería de Textos. Y por último y no menos importante, debe ser capaz de ofrecer mecanismos para mostrar de modo visual y sencillo analíticas resultantes tras procesar la información obtenida.
El objetivo principal de este proyecto es analizar, proponer y evaluar diferentes enfoques novedosos para el procesamiento de UGC desde un punto de vista analítico, creando una plataforma que combine, integre y visualice analíticas resultantes de distintos procesos de TLH.
Dichas analíticas pueden materializarse de distintas formas dependiendo de las necesidades y preferencias del usuario. Por ejemplo, pueden ser sintetizadas en forma de resúmenes, de tweets, valoración de opiniones, términos más relevantes, pasajes, recopilación de fuentes relevantes, geolocalización de los mensajes, autores, etc. Siendo conscientes que dicha información procede de la Web 2.0.
El núcleo del proceso tanto de recuperación y extracción como de procesamiento de la información estaría formado por técnicas y herramientas que conforman las TLH. Para ello, se integrarán tecnologías tales como el análisis semántico, recuperación y extracción de información, minería de opiniones, clasificación de textos, computación afectiva (o análisis de emociones), síntesis de textos y otras que puedan ser de utilidad durante el transcurso del proyecto. Aunque la plataforma no está limitada a la integración de otras tecnologías, sí que es cierto que estas tareas serán las que conformen su núcleo central, y por tanto, serán cruciales para el correcto desarrollo del proyecto.
Por tanto, el proceso de clasificación, análisis y presentación de estos textos implicaría en primer lugar decidir qué información se debe recuperar y seleccionarla. Posteriormente habrá que ser capaces de procesar dicha información. Para ello, será necesario identificar el tipo de información, clasificarla, detectar lo realmente importante y discriminar aquello que no es relevante, determinar información redundante, complementaria y/o contradictoria e integrar y combinar todo el conocimiento obtenido. Finalmente, todo el conocimiento obtenido quedará almacenado en un repositorio de minería de textos capaz de indexar toda aquella información que el usuario considere relevante para ser mostrado desde una óptica analítica mediante interfaces visuales.
El interés de este proyecto viene motivado por la necesidad de definir una plataforma basada en TLH que sea capaz de procesar la información de manera inteligente y de forma automática, combinando múltiples técnicas y herramientas. Además se flexibilizará el modo de mostrar visualmente los resultados y estos estarán adaptados a las necesidades de los usuarios y desde un punto de vista analítico. El avance científico en cada una de las TLH involucradas en la creación de la plataforma propuesta, así como su combinación e integración en una única infraestructura, supondría un gran paso dentro de esta área de investigación, siendo a su vez, de valiosa utilidad para la sociedad actual y futura.
Equipo de Investigación
- Yoan Gutiérrez Vázquez (Investigador Principal)
- Fernando Llopis Pascual (investigador)
- José Manuel Gómez Soriano (investigador)
- Lea Canales Zaragoza (investigadora)
- Antonio Guillen Espejo (investigador)
Producción científica
Registros de Software:
- GPLSI Sentiment Analysis V1.0: Análisis de sentimientos en textos (http://hdl.handle.net/10045/66436)
- Emotion Analysis V1.0: Análisis de emociones en textos (http://hdl.handle.net/10045/66410)
- GPLSI Wikipedia Characterisation V1.0: Descubrimiento y Vinculación de Entidades a Wikipedia (http://hdl.handle.net/10045/66373)
- Social Analytics Web Interface v2.0 http://hdl.handle.net/10045/74073
- Social Analytics Listener v2.0 http://hdl.handle.net/10045/74075
- Social Analytics Process v2.0 http://hdl.handle.net/10045/74074
- Social Analytics Database v2.0 http://hdl.handle.net/10045/74072
Revistas:
Article title: Spreading semantic information by Word Sense Disambiguation
Article reference: KNOSYS3941
Journal title: Knowledge-Based Systems
DOI information: 10.1016/j.knosys.2017.06.013- Article title: A Systemic and Cybernetic Perspective on Causality, Big Data, and Social Networks in Tourism
Article reference: K-02-2018-0084 Journal title: Kybernetes DOI information:10.1108/K-02-2018-0084
- Article title: Human Language Technologies: key issues for representing knowledge from textual information
Article reference: Journal title: Journal of Universal Computer Science
- Article title: Plataforma inteligente para la recuperación, análisis y representación de la información generada por usuarios en Internet Article reference:10.26342/2018-61-14
Journal title: Procesamiento del Lenguaje Natural
DOI information: http://dx.doi.org/10.26342/2018-61-14
Congresos:
Overview of TASS 2018: Opinions, Health and Emotions
Article reference: N/A
Conference title: Proceedings of TASS 2018: Workshop on Semantic Analysis at SEPLN (TASS 2018)
URL information: http://ceur-ws.org/Vol-2172/p0_overview_tass2018.pdfArticle title: Natural Language Processing Technologies for Document Profiling
Article reference: N/A
Conference title: Proceedings of Recent Advances in Natural Language Processing
URL information: doi.org/10.26615/978-954-452-049-6_039Article title: Opinion Mining in Social Networks versus Electoral Polls
Article reference: N/A
Conference title: Proceedings of Recent Advances in Natural Language Processing
URL information: https://doi.org/10.26615/978-954-452-049-6_032Article title: Towards the Improvement of Automatic Emotion Pre-annotation with Polarity and Subjective Information
Article reference: N/A
Conference title: Proceedings of Recent Advances in Natural Language Processing
URL information: https://doi.org/10.26615/978-954-452-049-6_022Article title: A Domain and Language Independent Named Entity Classification Approach Based on Profiles and Local Information
Article reference: N/A
Conference title: Proceedings of Recent Advances in Natural Language Processing
URL information: https://doi.org/10.26615/978-954-452-049-6_067Article title: Aproximación al modelado del ciberbullying desde las Tecnologías del Lenguaje Humano
Article reference: N/A
Conference title: Proceedings of Doctoral Symposium of the 33rd Conference of the Spanish Society for Natural Language Processing (SEPLN-DS 2017), Murcia, Spain, September 20, 2017.
URL information: http://ceur-ws.org/Vol-1961/paper03.pdfArticle title: Sentiment Analysis for Real-time Applications
Article reference: N/A
Conference title: PProceedings of Doctoral Symposium of the 33rd Conference of the Spanish Society for Natural Language Processing (SEPLN-DS 2017), Murcia, Spain, September 20, 2017.
URL information: http://ceur-ws.org/Vol-1961/paper08.pdfArticle title: Metodología semi-automática para la anotaci´on de corpus emocionales
Article reference: N/A
Conference title: Proceedings of Doctoral Symposium of the 33rd Conference of the Spanish Society for Natural Language Processing (SEPLN-DS 2017), Murcia, Spain, September 20, 2017.
URL information: http://ceur-ws.org/Vol-1961/paper10.pdfArticle title: ¿Cómo hacer perfiles de documentos?
Article reference: N/A
Conference title: Proceedings of Doctoral Symposium of the 33rd Conference of the Spanish Society for Natural Language Processing (SEPLN-DS 2017), Murcia, Spain, September 20, 2017.
URL information: http://ceur-ws.org/Vol-1961/paper02.pdfArticle title: Using the Twitter social network as a predictor in the political decision
Article reference: N/A
Conference title: 19th International Conference on Computational Linguistics and Intelligent Text Processing, March 18 to 24, 2018, Hanoi, Vietnam.
URL information: http://hdl.handle.net/10045/76464